| Question.56 DRAG DROP Match the Microsoft guiding principles for responsible AI to the appropriate descriptions. To answer, drag the appropriate principle from the column on the left to its description on the right. Each principle may be used once, more than once, or not at all. NOTE: Each correct selection is worth one point. Select and Place:  |
56. Click here to View Answer
Answer:

Box 1: Reliability and safety –
To build trust, it’s critical that AI systems operate reliably, safely, and consistently under normal circumstances and in unexpected conditions. These systems should be able to operate as they were originally designed, respond safely to unanticipated conditions, and resist harmful manipulation.
Box 2: Accountability –
The people who design and deploy AI systems must be accountable for how their systems operate. Organizations should draw upon industry standards to develop accountability norms. These norms can ensure that AI systems are not the final authority on any decision that impacts people’s lives and that humans maintain meaningful control over otherwise highly autonomous AI systems.
Box 3: Privacy and security –
As AI becomes more prevalent, protecting privacy and securing important personal and business information is becoming more critical and complex. With AI, privacy and data security issues require especially close attention because access to data is essential for AI systems to make accurate and informed predictions and decisions about people. AI systems must comply with privacy laws that require transparency about the collection, use, and storage of data and mandate that consumers have appropriate controls to choose how their data is used
Reference:
https://docs.microsoft.com/en-us/learn/modules/responsible-ai-principles/4-guiding-principles
| Question.57 You are developing a solution that uses the Text Analytics service. You need to identify the main talking points in a collection of documents. Which type of natural language processing should you use? A. entity recognition B. key phrase extraction C. sentiment analysis D. language detection |
57. Click here to View Answer
Answer: B
Broad entity extraction: Identify important concepts in text, including key
Key phrase extraction/ Broad entity extraction: Identify important concepts in text, including key phrases and named entities such as people, places, and organizations.
Reference:
https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/natural-language-processing
| Question.58 HOTSPOT To complete the sentence, select the appropriate option in the answer area. Hot Area:  |
58. Click here to View Answer
Answer:

Natural language processing (NLP) is used for tasks such as sentiment analysis, topic detection, language detection, key phrase extraction, and document categorization.
Reference:
https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/natural-language-processing
| Question.59 You need to predict the income range of a given customer by using the following dataset. 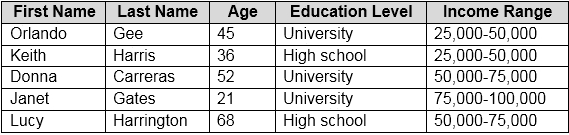 Which two fields should you use as features? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point. A. Education Level B. Last Name C. Age D. Income Range E. First Name |
59. Click here to View Answer
Answer: AC
First Name, Last Name, Age and Education Level are features. Income range is a label (what you want to predict). First Name and Last Name are irrelevant in that they have no bearing on income. Age and Education level are the features you should use.
| Question.60 HOTSPOT For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:  |
60. Click here to View Answer
Answer:

Box 1: Yes –
For regression problems, the label column must contain numeric data that represents the response variable. Ideally the numeric data represents a continuous scale.
Box 2: No –
K-Means Clustering –
Because the K-means algorithm is an unsupervised learning method, a label column is optional.
If your data includes a label, you can use the label values to guide selection of the clusters and optimize the model.
If your data has no label, the algorithm creates clusters representing possible categories, based solely on the data.
Box 3: No –
For classification problems, the label column must contain either categorical values or discrete values. Some examples might be a yes/no rating, a disease classification code or name, or an income group. If you pick a noncategorical column, the component will return an error during training.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/component-reference/train-model https://docs.microsoft.com/en-us/azure/machine-learning/component-reference/k-means-clustering