| Question.6 To complete the sentence, select the appropriate option in the answer area.  (A) inclusiveness (B) accountability (C) reliability and safety (D) fairness |
6. Click here to View Answer
Answer is (C) reliability and safety
AI systems need to be reliable and safe in order to be trusted. It’s important for a system to perform as it was originally designed and for it to respond safely to new situations. Its inherent resilience should resist intended or unintended manipulation. Rigorous testing and validation should be established for operating conditions to ensure that the system responds safely to edge cases, and A/B testing and champion/challenger methods should be integrated into the evaluation process.
| Question.7 You are building an AI system. Which task should you include to ensure that the service meets the Microsoft transparency principle for responsible AI? (A) Ensure that all visuals have an associated text that can be read by a screen reader. (B) Enable autoscaling to ensure that a service scales based on demand. (C) Provide documentation to help developers debug code. (D) Ensure that a training dataset is representative of the population. |
7. Click here to View Answer
Answer is (C) Provide documentation to help developers debug code.
Achieving transparency helps the team to understand the data and algorithms used to train the model, what transformation logic was applied to the data, the final model generated, and its associated assets. This information offers insights about how the model was created, which allows it to be reproduced in a transparent way. Snapshots within Azure Machine Learning workspaces support transparency by recording or retraining all training-related assets and metrics involved in the experiment.
| Question.8 Match the types of AI workloads to the appropriate scenarios. 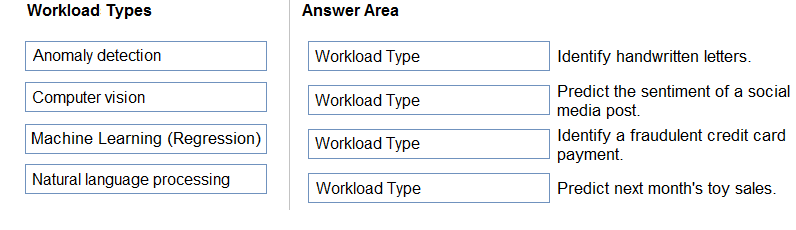 |
8. Click here to View Answer
Answer is
Computer vision = identify (object) letters
NLP = sentiment
Anomaly Detection = fraud
Maching Learning (regression) = predict
OCR or Optical Character Recognition is also referred to as text recognition or text extraction. Machine-learning based OCR techniques allow you to extract printed or handwritten text from images, such as posters, street signs and product labels, as well as from documents like articles, reports, forms, and invoices. The text is typically extracted as words, text lines, and paragraphs or text blocks, enabling access to digital version of the scanned text. This eliminates or significantly reduces the need for manual data entry.
Regression is a form of machine learning used to understand the relationships between variables to predict a desired outcome. Regression predicts a numeric label or outcome based on variables, or features. For example, an automobile sales company might use the characteristics of a car (such as engine size, number of seats, mileage, and so on) to predict its likely selling price. In this case, the characteristics of the car are the features, and the selling price is the label.
Sentiment analysis and opinion mining are features offered by Azure Cognitive Service for Language, a collection of machine learning and AI algorithms in the cloud for developing intelligent applications that involve written language. These features help you find out what people think of your brand or topic by mining text for clues about positive or negative sentiment, and can associate them with specific aspects of the text.
Anomaly Detector is an AI service with a set of APIs, which enables you to monitor and detect anomalies in your time series data with little machine learning (ML) knowledge, either batch validation or real-time inference.
Reference:
https://learn.microsoft.com/en-us/azure/cognitive-services/computer-vision/overview-ocr
https://learn.microsoft.com/en-us/training/modules/create-regression-model-azure-machine-learning-designer/2-regression-scenarios
https://learn.microsoft.com/en-us/azure/cognitive-services/language-service/sentiment-opinion-mining/overview
https://learn.microsoft.com/en-us/azure/cognitive-services/anomaly-detector/overview
| Question.9 Select the answer that correctly completes the sentence.  Key (A) phrase extraction Key (A) phrase extraction(B) Language detection (C) Named Entity Recognition (NER) (D) Sentiment Analysis |
9. Click here to View Answer
Answer is (C) Named Entity Recognition (NER)
The NER feature can identify and categorize entities in unstructured text. For example: people, places, organizations, and quantities.
| Question.10 For a machine learning progress, how should you split data for training and evaluation? (A) Use features for training and labels for evaluation. (B) Randomly split the data into rows for training and rows for evaluation. (C) Use labels for training and features for evaluation. (D) Randomly split the data into columns for training and columns for evaluation. |
10. Click here to View Answer
Answer is (B) Randomly split the data into rows for training and rows for evaluation.
The Split Data module is particularly useful when you need to separate data into training and testing sets. Use the Split Rows option if you want to divide the data into two parts. You can specify the percentage of data to put in each split, but by default, the data is divided 50-50. You can also randomize the selection of rows in each group, and use stratified sampling. Randomly 75-25 split on row may be a good idea.