| Question.56 You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool named SQLPool1. SQLPool1 is currently paused. You need to restore the current state of SQLPool1 to a new SQL pool. What should you do first? A. Create a workspace. B. Create a user-defined restore point. C. Resume SQLPool1. D. Create a new SQL pool. |
56. Click here to View Answer
Answer:
B
Explanation:
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-restore-
active-paused-dw
| Question.57 HOTSPOT You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool named Pool1 and an Azure Data Lake Storage account named storage1. Storage1 requires secure transfers. You need to create an external data source in Pool1 that will be used to read .orc files in storage1. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area: 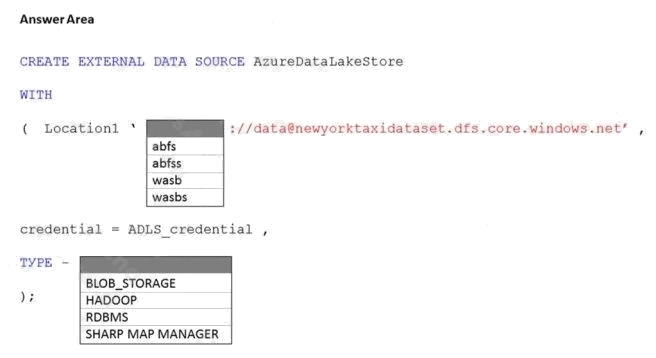 |
57. Click here to View Answer
Answer:
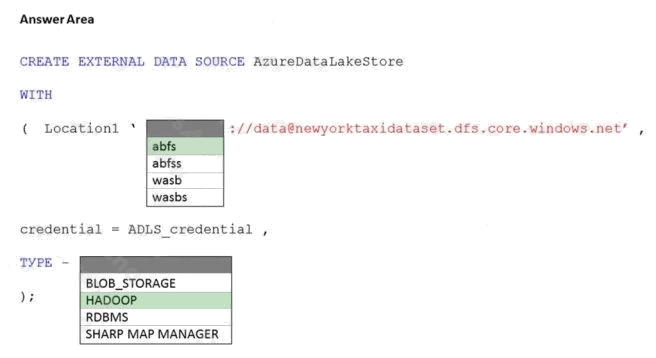
Explanation:
Reference: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-external-data-source-transact-sql?view=azure-
sqldw-latest&preserve-view=true&tabs=dedicated
| Question.58 DRAG DROP You have an Azure subscription that contains an Azure Synapse Analytics workspace named workspace1. Workspace1 connects to an Azure DevOps repository named repo1. Repo1 contains a collaboration branch named main and a development branch named branch1. Branch1 contains an Azure Synapse pipeline named pipeline1. In workspace1, you complete testing of pipeline1. You need to schedule pipeline1 to run daily at 6 AM. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select. Select and Place: 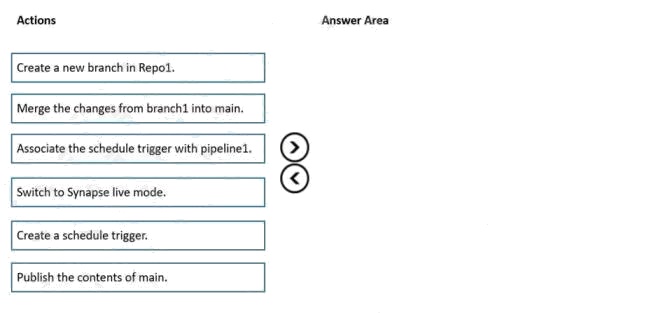 |
58. Click here to View Answer
Answer:

| Question.59 You have an Azure data factory named ADF1. You currently publish all pipeline authoring changes directly to ADF1. You need to implement version control for the changes made to pipeline artifacts. The solution must ensure that you can apply version control to the resources currently defined in the UX Authoring canvas for ADF1. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point. A. From the UX Authoring canvas, select Set up code repository. B. Create a Git repository. C. Create a GitHub action. D. Create an Azure Data Factory trigger. E. From the UX Authoring canvas, select Publish. F. From the UX Authoring canvas, run Publish All. |
59. Click here to View Answer
Answer:
B F
Explanation:
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/source-control
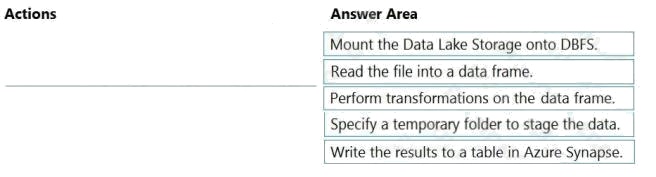
| Question.60 DRAG DROP You have an Azure Data Lake Storage Gen2 account that contains a JSON file for customers. The file contains two attributes named FirstName and LastName. You need to copy the data from the JSON file to an Azure Synapse Analytics table by using Azure Databricks. A new column must be created that concatenates the FirstName and LastName values. You create the following components: A destination table in Azure Synapse  An Azure Blob storage container  A service principal  In which order should you perform the actions? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:  |
60. Click here to View Answer
Answer:
Explanation:
Step 1: Mount the Data Lake Storage onto DBFS
Begin with creating a file system in the Azure Data Lake Storage Gen2 account.
Step 2: Read the file into a data frame.
You can load the json files as a data frame in Azure Databricks.
Step 3: Perform transformations on the data frame.
Step 4: Specify a temporary folder to stage the data
Specify a temporary folder to use while moving data between Azure Databricks and Azure Synapse.
Step 5: Write the results to a table in Azure Synapse.
You upload the transformed data frame into Azure Synapse. You use the Azure Synapse connector for Azure Databricks to
directly upload a dataframe as a table in a Azure Synapse.
Reference: https://docs.microsoft.com/en-us/azure/azure-databricks/databricks-extract-load-sql-data-warehouse