| Question .61 You have an Azure Synapse Analytics job that uses Scala. You need to view the status of the job. What should you do? A. From Synapse Studio, select the workspace. From Monitor, select SQL requests. B. From Azure Monitor, run a Kusto query against the AzureDiagnostics table. C. From Synapse Studio, select the workspace. From Monitor, select Apache Sparks applications. D. From Azure Monitor, run a Kusto query against the SparkLoggingEvent_CL table. |
61. Click here to View Answer
Answer:
C
Explanation:
Use Synapse Studio to monitor your Apache Spark applications. To monitor running Apache Spark application Open
Monitor, then select Apache Spark applications. To view the details about the Apache Spark applications that are running,
select the submitting Apache Spark application and view the details. If the Apache Spark application is still running, you can
monitor the progress.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/monitoring/apache-spark-applications
| Question.62 You have an Azure Data Factory pipeline that is triggered hourly. The pipeline has had 100% success for the past seven days. The pipeline execution fails, and two retries that occur 15 minutes apart also fail. The third failure returns the following error. ErrorCode=UserErrorFileNotFound,’Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=ADL S Gen2 operation failed for: Operation returned an invalid status code ‘NotFound’. Account: ‘contosoproduksouth’. Filesystem: wwi. Path: ‘BIKES/CARBON/year=2021/month=01/day=10/hour=06’. ErrorCode: ‘PathNotFound’. Message: ‘The specified path does not exist.’. RequestId: ‘6d269b78-901f-001b-4924-e7a7bc000000’. TimeStamp: ‘Sun, 10 Jan 2021 07:45:05 What is a possible cause of the error? A. The parameter used to generate year=2021/month=01/day=10/hour=06 was incorrect. B. From 06:00 to 07:00 on January 10, 2021, there was no data in wwi/BIKES/CARBON. C. From 06:00 to 07:00 on January 10, 2021, the file format of data in wwi/BIKES/CARBON was incorrect. D. The pipeline was triggered too early. |
62. Click here to View Answer
Answer:
A
| Question.63 You have an activity in an Azure Data Factory pipeline. The activity calls a stored procedure in a data warehouse in Azure Synapse Analytics and runs daily. You need to verify the duration of the activity when it ran last. What should you use? A. activity runs in Azure Monitor B. Activity log in Azure Synapse Analytics C. the sys.dm_pdw_wait_stats data management view in Azure Synapse Analytics D. an Azure Resource Manager template |
63. Click here to View Answer
Answer:
A
Explanation:
Monitor activity runs. To get a detailed view of the individual activity runs of a specific pipeline run, click on the pipeline
name. Example: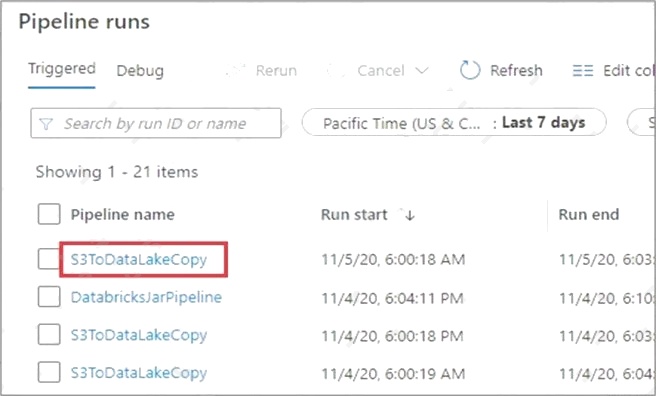
The list view shows activity runs that correspond to each pipeline run. Hover over the specific activity run to get run-specific
information such as the JSON input, JSON output, and detailed activity-specific monitoring experiences.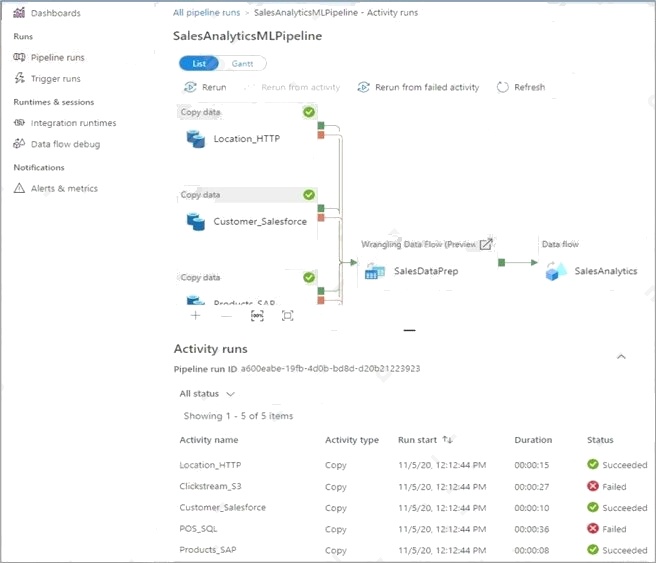
You can check the Duration.
Incorrect Answers:
C: sys.dm_pdw_wait_stats holds information related to the SQL Server OS state related to instances running on the different
nodes.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/monitor-visually
| Question.64 You have an Azure Stream Analytics job. You need to ensure that the job has enough streaming units provisioned. You configure monitoring of the SU % Utilization metric. Which two additional metrics should you monitor? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point. A. Backlogged Input Events B. Watermark Delay C. Function Events D. Out of order Events E. Late Input Events |
64. Click here to View Answer
Answer:
A B
Explanation:
To react to increased workloads and increase streaming units, consider setting an alert of 80% on the SU Utilization metric.
Also, you can use watermark delay and backlogged events metrics to see if there is an impact.
Note: Backlogged Input Events: Number of input events that are backlogged. A non-zero value for this metric implies that
your job isn’t able to keep up with the number of incoming events. If this value is slowly increasing or consistently non-zero,
you should scale out your job, by increasing the SUs.
Reference:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-monitoring
| Question.65 HOTSPOT You are designing an enterprise data warehouse in Azure Synapse Analytics that will store website traffic analytics in a star schema. You plan to have a fact table for website visits. The table will be approximately 5 GB. You need to recommend which distribution type and index type to use for the table. The solution must provide the fastest query performance. What should you recommend? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area: 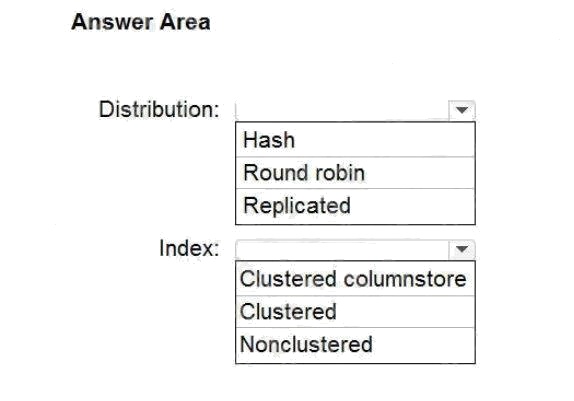 |
65. Click here to View Answer
Answer:
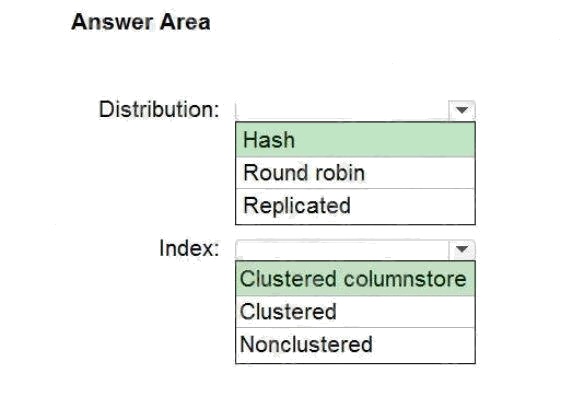
Explanation:
Box 1: Hash
Consider using a hash-distributed table when:
The table size on disk is more than 2 GB.
The table has frequent insert, update, and delete operations.
Box 2: Clustered columnstore
Clustered columnstore tables offer both the highest level of data compression and the best overall query performance.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribute
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-index