| Question.21 You implement an enterprise data warehouse in Azure Synapse Analytics. You have a large fact table that is 10 terabytes (TB) in size. Incoming queries use the primary key SaleKey column to retrieve data as displayed in the following table:  You need to distribute the large fact table across multiple nodes to optimize performance of the table. Which technology should you use? A. hash distributed table with clustered index B. hash distributed table with clustered Columnstore index C. round robin distributed table with clustered index D. round robin distributed table with clustered Columnstore index E. heap table with distribution replicate |
21. Click here to View Answer
Answer: B
Explanation:
Hash-distributed tables improve query performance on large fact tables.
Columnstore indexes can achieve up to 100x better performance on analytics and data warehousing workloads and up to
10x better data compression than traditional rowstore indexes.
Incorrect Answers:
C, D: Round-robin tables are useful for improving loading speed.
Reference: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-distribute
https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-query-performance
| Question.22 You have a partitioned table in an Azure Synapse Analytics dedicated SQL pool. You need to design queries to maximize the benefits of partition elimination. What should you include in the Transact-SQL queries? A. JOIN B. WHERE C. DISTINCT D. GROUP BY |
22. Click here to View Answer
Answer: B
| Question.23 HOTSPOT You have an on-premises data warehouse that includes the following fact tables. Both tables have the following columns: DateKey, ProductKey, RegionKey. There are 120 unique product keys and 65 unique region keys.  Queries that use the data warehouse take a long time to complete. You plan to migrate the solution to use Azure Synapse Analytics. You need to ensure that the Azure-based solution optimizes query performance and minimizes processing skew. What should you recommend? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point Hot Area: 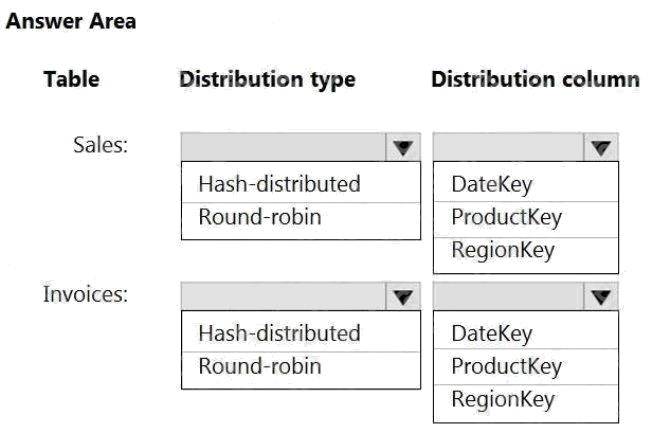 |
23. Click here to View Answer
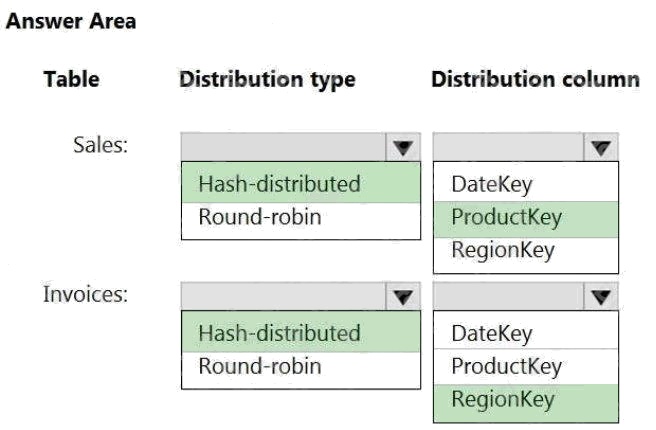
Answer:
Explanation:
Box 1: Hash-distributed
Box 2: ProductKey
ProductKey is used extensively in joins.
Hash-distributed tables improve query performance on large fact tables.
Box 3: Hash-distributed
Box 4: RegionKey
Round-robin tables are useful for improving loading speed.
Consider using the round-robin distribution for your table in the following scenarios:
When getting started as a simple starting point since it is the default
If there is no obvious joining key
If there is not good candidate column for hash distributing the table
If the table does not share a common join key with other tables
If the join is less significant than other joins in the query When the table is a temporary staging table

Note: A distributed table appears as a single table, but the rows are actually stored across 60 distributions. The rows are
distributed with a hash or round-robin algorithm. Reference:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-distribute
| Question.24 HOTSPOT You have an Azure event hub named retailhub that has 16 partitions. Transactions are posted to retailhub. Each transaction includes the transaction ID, the individual line items, and the payment details. The transaction ID is used as the partition key. You are designing an Azure Stream Analytics job to identify potentially fraudulent transactions at a retail store. The job will use retailhub as the input. The job will output the transaction ID, the individual line items, the payment details, a fraud score, and a fraud indicator. You plan to send the output to an Azure event hub named fraudhub. You need to ensure that the fraud detection solution is highly scalable and processes transactions as quickly as possible. How should you structure the output of the Stream Analytics job? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area: 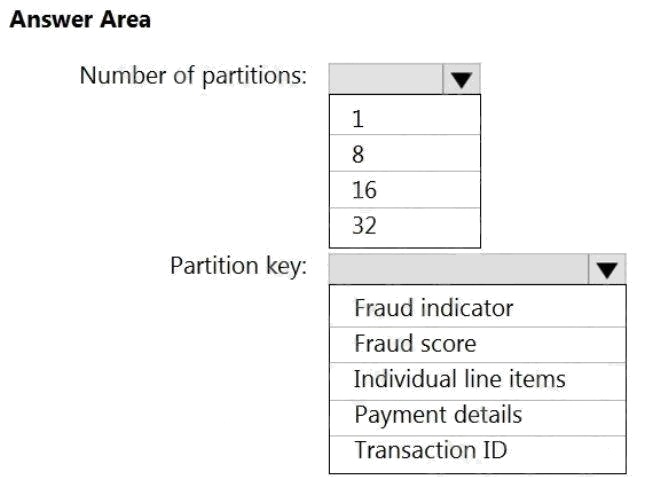 |
24. Click here to View Answer
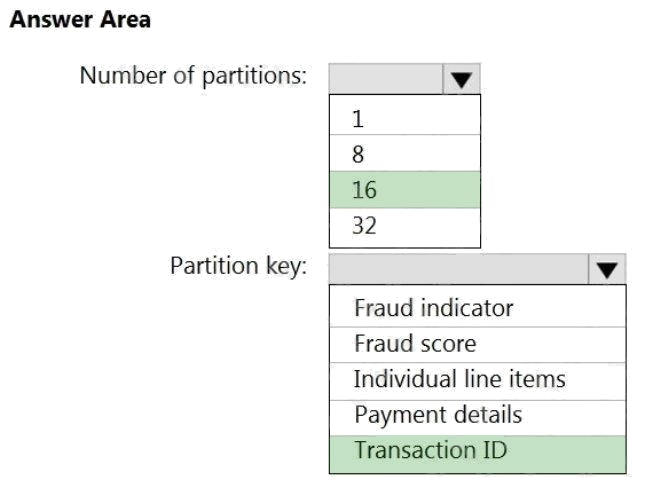
Answer:
Explanation:
Box 1: 16
For Event Hubs you need to set the partition key explicitly.
An embarrassingly parallel job is the most scalable scenario in Azure Stream Analytics. It connects one partition of the input
to one instance of the query to one partition of the output. Box 2: Transaction ID
Reference: https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-features#partitions
| Question.25 A company purchases IoT devices to monitor manufacturing machinery. The company uses an Azure IoT Hub to communicate with the IoT devices. The company must be able to monitor the devices in real-time. You need to design the solution. What should you recommend? A. Azure Analysis Services using Azure PowerShell B. Azure Data Factory instance using Azure PowerShell C. Azure Stream Analytics cloud job using Azure Portal D. Azure Data Factory instance using Microsoft Visual Studio |
25. Click here to View Answer
Answer: C
Explanation:
In a real-world scenario, you could have hundreds of these sensors generating events as a stream. Ideally, a gateway device
would run code to push these events to Azure Event Hubs or Azure IoT Hubs. Your Stream Analytics job would ingest these
events from Event Hubs and run real-time analytics queries against the streams.
Create a Stream Analytics job:
In the Azure portal, select + Create a resource from the left navigation menu. Then, select Stream Analytics job from
Analytics.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-get-started-with-azure-stream-
analytics-to-process-data-from-iot-devices