| Question.36 You have a SQL pool in Azure Synapse that contains a table named dbo.Customers. The table contains a column name Email. You need to prevent nonadministrative users from seeing the full email addresses in the Email column. The users must see values in a format of aXXX@XXXX.com instead. What should you do? A. From Microsoft SQL Server Management Studio, set an email mask on the Email column. B. From the Azure portal, set a mask on the Email column. C. From Microsoft SQL Server Management Studio, grant the SELECT permission to the users for all the columns in the dbo.Customers table except Email. D. From the Azure portal, set a sensitivity classification of Confidential for the Email column. |
36. Click here to View Answer
Answer:
A
Explanation:
The Email masking method, which exposes the first letter and replaces the domain with XXX.com using a constant string
prefix in the form of an email address.
aXX@XXXX.com
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/dynamic-data-masking-overview
| Question.37 You are designing a security model for an Azure Synapse Analytics dedicated SQL pool that will support multiple companies. You need to ensure that users from each company can view only the data of their respective company. Which two objects should you include in the solution? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point. A. a security policy B. a custom role-based access control (RBAC) role C. a predicate function D. a column encryption key E. asymmetric keys |
37. Click here to View Answer
Answer:
A B
Explanation:
A: Row-Level Security (RLS) enables you to use group membership or execution context to control access to rows in a
database table. Implement RLS by using the CREATE SECURITY POLICYTransactSQL statement.
B: Azure Synapse provides a comprehensive and fine-grained access control system, that integrates:
Azure roles for resource management and access to data in storage, Synapse roles for managing live access to code

and execution, SQL roles for data plane access to data in SQL pools.
Reference: https://docs.microsoft.com/en-us/sql/relational-databases/security/row-level-security
https://docs.microsoft.com/en-us/azure/synapse-analytics/security/synapse-workspace-access-control-overview
| Question.38 HOTSPOT You develop a dataset named DBTBL1 by using Azure Databricks. DBTBL1 contains the following columns: SensorTypeID  GeographyRegionID  Year  Month  Day  Hour  Minute  Temperature  WindSpeed  Other  You need to store the data to support daily incremental load pipelines that vary for each GeographyRegionID. The solution must minimize storage costs. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area: 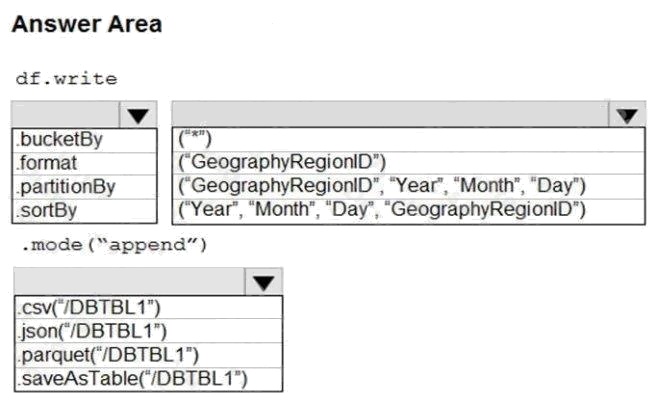 |
38. Click here to View Answer
Answer:
Explanation:
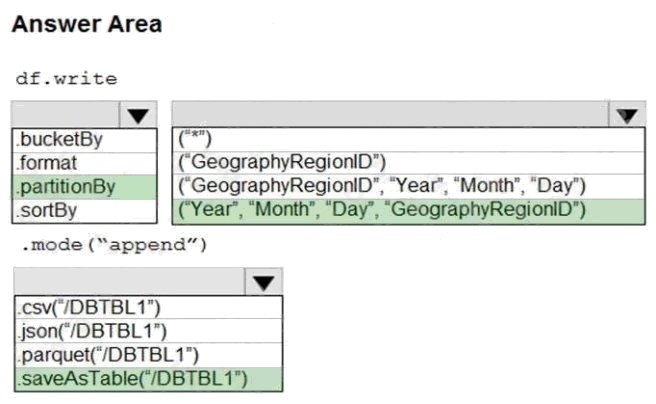
Box 1: .partitionBy
Incorrect Answers:
.format:
Method: format():
Arguments: “parquet”, “csv”, “txt”, “json”, “jdbc”, “orc”, “avro”, etc.
.bucketBy:
Method: bucketBy()
Arguments: (numBuckets, col, col…, coln)
The number of buckets and names of columns to bucket by. Uses Hives bucketing scheme on a filesystem.
Box 2: (“Year”, “Month”, “Day”,”GeographyRegionID”)
Specify the columns on which to do the partition. Use the date columns followed by the GeographyRegionID column.
Box 3: .saveAsTable(“/DBTBL1”)
Method: saveAsTable()
Argument: “table_name” The table to save to.
Reference: https://www.oreilly.com/library/view/learning-spark-2nd/9781492050032/ch04.html https://docs.microsoft.com/en-
us/azure/databricks/delta/delta-batch
| Question.39 You are designing a date dimension table in an Azure Synapse Analytics dedicated SQL pool. The date dimension table will be used by all the fact tables. Which distribution type should you recommend to minimize data movement during queries? A. HASH B. REPLICATE C. ROUND_ROBIN |
39. Click here to View Answer
Answer:
B
Explanation:
A replicated table has a full copy of the table available on every Compute node. Queries run fast on replicated tables since
joins on replicated tables don’t require data movement. Replication requires extra storage, though, and isn’t practical for
large tables.
Incorrect Answers:
A: A hash distributed table is designed to achieve high performance for queries on large tables.
C: A round-robin table distributes table rows evenly across all distributions. The rows are distributed randomly. Loading data
into a round-robin table is fast. Keep in mind that queries can require more data movement than the other distribution
methods.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-overview
| Question.40 You are designing a streaming data solution that will ingest variable volumes of data. You need to ensure that you can change the partition count after creation. Which service should you use to ingest the data? A. Azure Event Hubs Dedicated B. Azure Stream Analytics C. Azure Data Factory D. Azure Synapse Analytics |
40. Click here to View Answer
Answer:
A
Explanation:
You can’t change the partition count for an event hub after its creation except for the event hub in a dedicated cluster.
Reference:
https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-features